Using Catalog Zones in BIND to Configure Slave DNS Servers
I was recently asked to help one of my friends think about re-architecting his anycast DNS service, so I’ve been thinking about DNS a lot on the backburner for the last few months. As part of that, I was idly reading through the whole ISC knowledge base this week, since they’ve got a lot of really good documentation on BIND and DNS, and I stumbled across a short article talking about catalog zones.
Catalog zones are this new concept (well, kind of new; there’s speculative papers about the concept going back about a decade) where you use DNS and the existing AXFR transfer method to move configuration parameters from a master DNS server to its slaves.
In the context of the anycast DNS service I’m working on now, this solves a pretty major issue which is the question on how to push new configuration changes to all of the nodes. This DNS service is a pretty typical secondary authoritative DNS service with a hidden master. This means that our users are expected to run their own DNS servers serving their zones, and we then have one hidden master which transfers zones from all these various users’ servers, and then redistribute the zones to the handful of identical slave servers distributed worldwide which all listen on the same anycast prefix addresses.
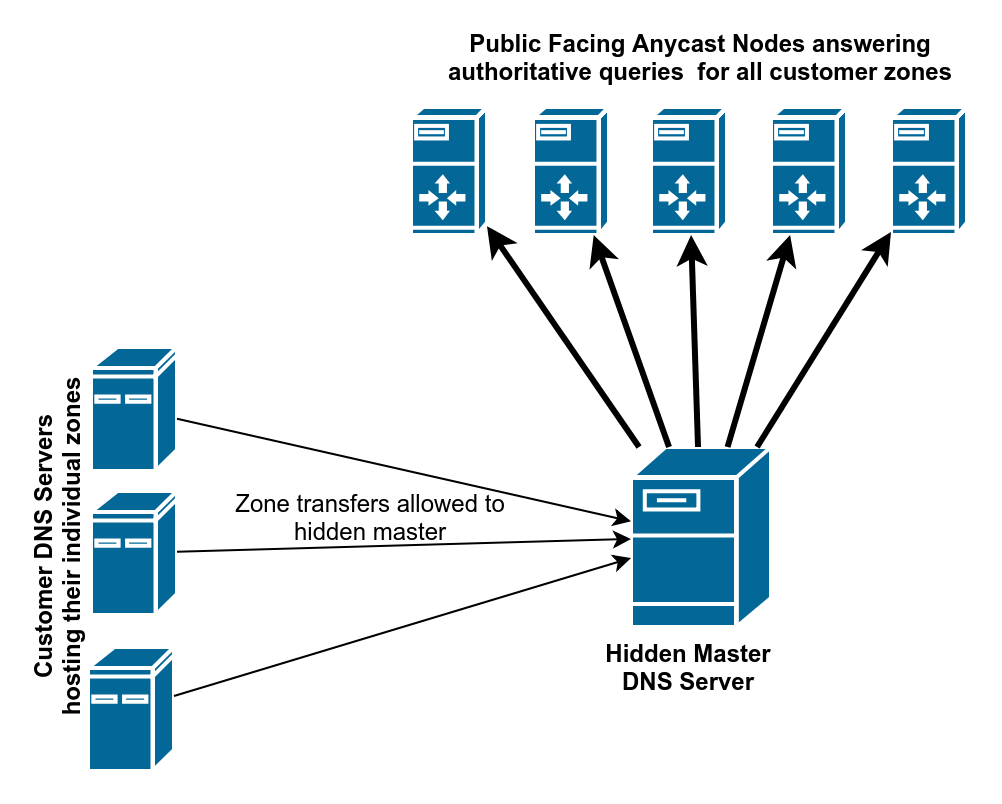
Updates to existing zones is a standard part of the DNS protocol, where the customer updates their zone locally, and when they increment their SOA serial number, their server sends a notify to our hidden master, which initiates a zone transfer to get the latest version of their zone, and then sends a notify to the pool of anycast slaves to all update their copy of the customer zone from the hidden master. Thanks to the notify feature in DNS, pushing an updated zone to all of these slave authoritative servers happens pretty quickly, so the rest of the Internet sending queries to the anycast node nearest to them start seeing the new zone updates right away.
The problem is when you want to add new zones to this whole pipeline. After our customer has created the new zone on their server and allowed transfers from our master, we need to configure our hidden master as a slave for that zone pointed to the customer server, and we need to configure all of the anycast nodes to be a slave for the zone pointed back at our hidden master. If we miss one, you start experiencing very hard to troubleshoot issues where it seems like we aren’t correctly being authoritative for the new zone, but only in certain regions of the Internet depending on which specific anycast node you’re hitting. Anycast systems really depend on all the instances seeming identical, so it doesn’t matter which one you get routed to.
There are, of course, hundreds of different ways to automate the provisioning of these new zones on all of the anycast nodes, so this isn’t an unsolved issue, but the possible solutions range anywhere from a bash for loop calling rsync and ssh on each node to using provisioning frameworks like Ansible to reprovision all the nodes any time the set of customer zones changes.
Catalog zones is a clever way to move this issue of configuring a slave DNS server for what zones it should be authoritative for into the DNS protocol itself, by having the slaves transfer a specially formatted zone from the master which lists PTR records for each of the other zones to be authoritative for. This means that adding a new zone to the slaves no longer involves changing any of the BIND configuration files on the slave nodes and reloading, but instead is a DNS notify from the master that the catalog zone has changed, an AXFR of the catalog zone, and then parsing this zone to configure all of the zones to also transfer from the master. DNS is already a really good protocol for moving dynamic lists of records around using the notify/AXFR/IXFR mechanism, so using it to also manage the dynamic list of zones to do this for is in my opinion genius.
Labbing It at Home
So after reading the ISC article on catalog zones, and also finding an article by Jan-Piet on the matter, I decided to spin up two virtual machines and have a go at using this new feature available in BIND 9.11.
A couple things to note before getting into it:
- Catalog zones are a pretty non-standard feature which is currently only supported by BIND. There's a draft RFC on catalog zones, which has already moved past version 1 supported in BIND, so changes are likely for this feature in the future.
- Both of the tutorials I read happened to use BIND for the master serving the catalog zone, and used rndc to dynamically add new zones to the running server, but this isn't required. Particularly since we're using a hidden master configuration, there's no downside to generating the catalog zone and corresponding zone configurations on the master using any provisioning system you like, and simply restarting or reloading that name server to pick up the changes and distribute them to the slaves, since the hidden master is only acting as a relay to collect all the zones from various customers and serve as a single place for all the anycast slaves to transfer zones from.
- This catalog zone feature doesn't even depend on the master server running BIND. As far as the master is concerned, the catalog zone is just another DNS zone, which it serves just like any other zone. It's only the slaves which receive the catalog zone which need to be able to parse the catalog to dynamically add other zones based on what they receive.
We want to keep this exercise as simple as possible, so we’re not doing anything involving anycast, hidden masters, or adding zones to running servers. We’re only spinning up two servers, in this case both running Ubuntu 18.04, but any distro which includes BIND 9.11 should work:
- ns1.lan.thelifeofkenneth.com (10.44.1.228) - A standard authoritative server serving the zones "catalog.ns1.lan.thelifeofkenneth.com", "zone1.example.com", and "zone2.example.com". This server is acting as our source of zone transfers, so there's nothing special going on here except sending notify messages and zone transfers to our slave DNS server.
- ns2.lan.thelifeofkenneth.com (10.44.1.234) - A slave DNS server running BIND 9.11 and configured to be a slave to ns1 for the zone "catalog.ns1.lan.thelifeofkenneth.com" and to use this zone as a catalog zone with ns1 (10.44.1.228) as the default master. Via this catalog zone, ns2 will add "zone1.example.com" and "zone2.example.com" and transfer those zones from ns1.
We first want to set up ns1, which is a normal authoritative DNS configuration, with the one addition that I added logging for transfers, since that’s what we’re playing with here.
options {
directory "/var/cache/bind";
dnssec-validation auto;
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
recursion no;
};
logging {
channel zone_transfers_log {
file "/var/cache/bind/zone_transfers" versions 3 size 20m;
print-time yes;
print-category yes;
print-severity yes;
severity info;
};
category notify { zone_transfers_log; };
category xfer-in { zone_transfers_log; };
category xfer-out { zone_transfers_log; };
};
Nothing too unexpected there; turn off recursion service, and turn on logging.
The only particularly unusual thing about the definition of the zone files is that I’m explicitly listing the IP address for the slave server under “also-notify”. I’m doing that here because I couldn’t get it to work based on the NS records like I think it should, but that might also be because I’m using zones not actually delegated to me.
zone "catalog.ns1.lan.thelifeofkenneth.com" {
type master;
file "/etc/bind/catalog.db";
allow-transfer { any; };
also-notify {10.44.1.234; };
};
zone "zone1.example.com" {
type master;
file "/etc/bind/zone1.example.com.db";
allow-transfer { any; };
also-notify {10.44.1.234; };
};
zone "zone2.example.com" {
type master;
file "/etc/bind/zone2.example.com.db";
allow-transfer { any; };
also-notify {10.44.1.234; };
};
In my actual application, I’ll need to to use also-notify anyways, because I need to send notify messages to every anycast node instance on their unicast addresses. In a real application I would also lock down the zone transfers to only allow my slaves to transfer zones from the master, since it’s generally bad practice to allow anyone to download your whole zone file.
zone1.example.com. 3600 IN SOA . . 4 2d 15m 1000h 5m
zone1.example.com. IN NS ns1.lan.thelifeofkenneth.com.
zone1.example.com. IN NS ns2.lan.thelifeofkenneth.com.
test IN TXT "hello world"
zone2.example.com. 3600 IN SOA . . 4 2d 15m 1000h 5m
zone2.example.com. IN NS ns1.lan.thelifeofkenneth.com.
zone2.example.com. IN NS ns2.lan.thelifeofkenneth.com.
test IN TXT "hello world2"
The two example.com zone files are also pretty unremarkable.
Up until this point, you haven’t actually seen anything relevant to the catalog zone, so this is where you should start paying attention! The last file on ns1 of importance is the catalog file itself, which we’ll dig into next:
catalog.ns1.lan.thelifeofkenneth.com. IN SOA . . 14 2d 15m 1000h 5m
catalog.ns1.lan.thelifeofkenneth.com. IN NS ns1.lan.thelifeofkenneth.com.
version IN TXT "1"
ddb8c2c4b7c59a9a3344cc034ccb8637f89ff997.zones IN PTR zone1.example.com.
12b1bb2a76ba242857318440f4fc9f7d35e9c4ed.zones IN PTR zone2.example.com.
Ok, so that might look pretty hairy, so let us step through that line by line.
- Line 1: A standard start of authority record for the zone. A lot of the examples use dummy zones like "catalog.meta" or "catalog.example" for the catalog zone, but I don't like trying to come up with fake TLDs which I just have to hope isn't going to become a valid TLD later, so I named my catalog zone under my name server's hostname. In reality, the name of this zone does not matter, because no one should ever be sending queries against it; it's just a zone to be transferred to the slaves and processed there.
- Line 3: Every zone needs an NS record, which again can be made a dummy record if you'd like, because no one should ever be querying this zone.
- Line 5: To tell the slaves to parse this catalog zone as a version 1 catalog format, we create a TXT record for "version" with a value of "1". It's important to remember the importance of a trailing dot on record names! Since "version" doesn't end in a dot, the zone is implicitly appended to it, so you could also define this record as "version.catalog.ns1.lan.thelifeofkenneth.com." but that's a lot of typing to be repeated, so we don't.
- Lines 7 and 8: This is where the actual magic happens, by defining unique PTR records with values for each of the zones which this catalog file is listing for the slaves to be authoritative for. This is somewhat of an abuse of the PTR record meaning, but adding new record types has proven impractical, so here we are. Each record is a [unique identifier].zones.catalog.... etc.
The one trick with the version 1 catalog zone that’s implemented by BIND is that the value of the unique identifier per cataloged zone is pretty specific. It is the hexadecimal representation of the SHA1 sum of the on-the-wire format of the cataloged zone.
I’ve thought about it quite a bit, and while I can see some advantages to using a stable unique identifier like this per PTR record, I don’t grasp why BIND should strictly require it, and reading the version 2 spec in the draft RFC, it looks like they might loosen this up in the future, but for now we need to generate the exact hostname expected for each zone. I did this by adding a python script to my local system based on Jan-Piet’s code:
#!/usr/bin/env python3
import dns.name
import hashlib
import sys
print (hashlib.sha1(dns.name.from_text(sys.argv[1]).to_wire()).hexdigest())
I needed to install the dnspython package (pip3 install dnspython), but I could then use this python script to calculate the hash for each zone, and add it to my catalog zone by appending “.zones” to it and adding it as a PTR record with the value of the zone itself.
So looking back at line 7 of the catalog zone file, by running this python script as dns-catalog-hash zone1.example.com the python script spit out the hash ddb8c2c4b7c59a9a3344cc034ccb8637f89ff997 which is why I used that for the record name.
Now before we talk about the slave name server, I want to again emphasize that we haven’t utilized any unusual features yet. NS1 is just a normal DNS server serving normal DNS zones, so generate the catalog zone file any way you like, and ns1 can be running any DNS daemon which you like. Adding each new zone to ns1 involves adding it to the daemon config like usual, and the only additional step is also adding it as a PTR record to the catalog zone.
On to ns2! This is where things start to get exciting, because what I show you here will be the only change ever needed on ns2 to continue to serve any additional zones we like based on the catalog zone.
options {
directory "/var/cache/bind";
dnssec-validation auto;
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
recursion no;
catalog-zones {
zone "catalog.ns1.lan.thelifeofkenneth.com" default-masters { 10.44.1.228; };
};
};
logging {
channel zone_transfers_log {
file "/var/cache/bind/zone_transfers" versions 3 size 20m;
print-time yes;
print-category yes;
print-severity yes;
severity info;
};
category notify { zone_transfers_log; };
category xfer-in { zone_transfers_log; };
category xfer-out { zone_transfers_log; };
};
Again, we’ve turned off recursion, and turned on transfer logging to help us see what’s going on, but the important addition to the BIND options config is the addition of the catalog-zones directive. This tells the slave to parse the named zone as a catalog zone. We do explicitly tell it to assume the master for each new zone should be 10.44.1.228, but the catalog zone format actually supports you explicitly defining per zone configuration directives like masters, etc. So just appreciate that we’re using the bare minimum of the catalog zone feature here by just adding new zones to transfer from the default master.
// This is the only zone explicitly configured for ns2, and that's what makes this amazing!
zone "catalog.ns1.lan.thelifeofkenneth.com" {
type slave;
file "catalog.db";
masters { 10.44.1.228; };
};
This is the totally cool part about catalog zones right here; our local zones config file just tells the slave where to get the catalog from, and BIND takes it from there based on what it gets from the catalog.
If you fire up both of these daemons, with IP addresses and domain names changed to suit your lab environment, and watch the /var/cache/bind/zone_transfers log files, you should see:
- ns1 fires off notify messages for all the zones
- ns2 start a transfer of catalog.ns1.lan.thelifeofkenneth.com and processes it
- Based on that catalog file ns2 starts additional transfers for zone1.example.com and zone2.example.com
- Both ns1 and ns2 are now authoritative for zone[12].example.com!
To verify that ns2 is being authoritative like it should be, you can send it queries like dig txt test.zone1.example.com @ns2.lan.thelifeofkenneth.com and get the appropriate answer back.
You can also look in the ns2:/var/cache/bind/ directory to confirm that it has local caches for the catalog and example.com zones:
kenneth@ns2:~$ ls /var/cache/bind/
catalog.db
__catz___default_catalog.ns1.lan.thelifeofkenneth.com_zone1.example.com.db
__catz___default_catalog.ns1.lan.thelifeofkenneth.com_zone2.example.com.db
managed-keys.bind
managed-keys.bind.jnl
zone_transfers
The catalog file is cached in whatever filename you set for it in the named.conf.local file, but we never told it what filenames to use for each of the cataloged zones, so BIND came up with its own filenames for zone[12].example.com starting with “catz” and based on the catalog zone’s name and each zone’s name itself.
Final thoughts
I find this whole catalog zone concept really appealing since it’s such an elegant solution to exactly the problem I’ve been pondering for quite a while.
It’s important to note that this set of example configs aren’t production worthy, since this was just me in a sandbox over two evenings. A couple problems off the top of my head:
- You should be locking down zone transfers so only the slaves can AXFR the catalog zone and all of your other zones, since otherwise someone could enumerate all of your zones and all the hosts on those zones.
- You probably should disallow even any queries against the catalog zone. I didn't, since it made debugging the zone transfers easier, but I can see the downside to answering queries out of the catalog. It wouldn't help enumerate zones, since it'd be easier to guess zone names and query for their SOAs than guessing the SHA1 sums of the same zone names and asking for the PTR record for it out of the catalog, but if you start using more sophisticated features of the catalog zone like defining per-zone masters or other configuration parameters, you might not want to allow those to be available for query by the public.