How Tomato's Quality of Service Actually Works

I previously talked about the growing buffering problem on the Internet, where grossly over-sized buffers cause the latency of links under load to spike into hundreds of ms or even several seconds, and how to try and prioritize and meter your own Internet traffic to do what you can to mitigate the issue using the third-party Tomato firmware and its QoS (Quality of Service) feature.
Of course, that entire introduction only dealt with the shiny and colorful web interface provided by Tomato to talk to the QoS software stack, and like all things in Linux, this web interface is but only a wrapper around a set of painfully baroque command line tools.
And for my next trick, I pull back the curtain and show you how Tomato’s QoS system actually works!
This will show what all of the rules written through the web interface actually effect in the router, and give you a really good window into how traffic is thus handled. I will admit that this discussion will be a rather academic affair more than anything else, since embedded environments such as routers tend to not lend themselves well to easily reaching into a live running system and tweaking stuff on the back-end, and what tools that are available tend to be severely lobotomized to cut down on memory requirements. If the router happened to be running a full software stack from a normal filesystem, you could tear everything apart and put it back together any way you want on the fly, but Tomato runs from a read-only filesystem and the tools aren’t smart enough to change many settings even if they were able to. If you’re willing and able to build your own router with an actual computer motherboard and a fistful of NICs, you can use a real Linux (or other unix) distribution which lets you change these things, but that will be more work than plugging in a WRT54G, and likely much more expensive…
The first step is to get shell access on the router to be able to run commands, preferably using ssh. Some firmwares (such as DD-WRT) allow you to run shell commands through the web interface and will display the results, but Tomato doesn’t happen to offer this ability. To enable ssh access, go to the Admin Access tab (http://192.168.1.1/admin-access.asp) and start the SSH Daemon. For operating systems which already happen to have an ssh client installed (pretty much everything except Windows), logging in only takes running the following command from your computer:
$ ssh root@192.168.1.1
For Windows, you will need to download and install some form of SSH client. My personal favorite is PuTTY. Hopefully establishing this ssh connection will be successful, and the router will come back prompting you for root’s password (which is the same as “admin” through the web interface). Unix doesn’t print ***** while you type in passwords like you might expect, so type in your password blind and hit return. It should drop you to a prompt (“#”), where you can then type in commands to be run on your router.
Needless to say, while poking around on your router’s shell as root, do be careful. It takes less work than you’d think to turn your lovely WRT54G router into a dead piece of e-waste, and a LOT of work to bring it back (but still often possible). When you do brick your router, appreciate that it was YOUR fault, and hold me in no way liable.
Before poking around on the shell, lets first consider the physical hardware which we will be interrogating, so that some of Linux’s subsequent responses will hopefully make some more sense.

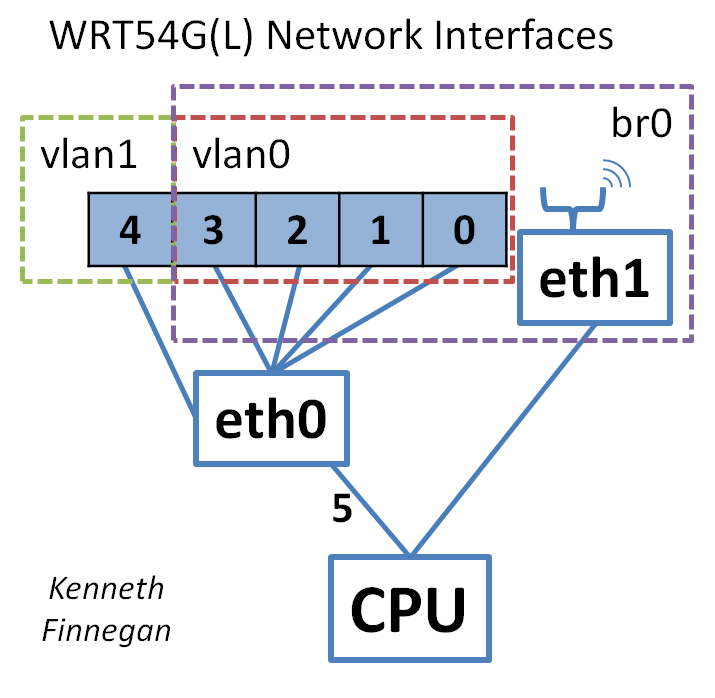
The networking hardware in the typical WRT54G(L) is comprised of three major components. The picture shows a random carcass out of my eWaste bin, which looks like a WRT54Gv1.1, but the differences between revisions is trivial:
- BCM4702KPB - This is the Broadcom MIPS CPU that the Linux operating system runs on.
- ADM6996 (eth0) - This is a six-port programmable Ethernet controller, which is connected to the four LAN Ethernet ports, the WAN port, and to the CPU, which enumerates it as eth0 in “ifconfig.” An important thing to note is that since this controller is intelligent, once it is configured it will automatically switch local Ethernet traffic without the CPU ever seeing it, and only show the CPU traffic from the WAN port and anything leaving the switched LAN.
- BCM4306KFB (eth1) - This is the controller for 802.11b/g WiFi, passing traffic between the CPU and any wireless devices on the network.
The primary point to take away from this is that the five Ethernet ports on the back all feed into one controller, which is separate from the processor. This means that Linux can program it to bond the four local ports together, and the CPU then only has to handle any traffic going between this set of ports and WiFi or the Internet. This is done via segregating eth0 into several “virtual lans,” which look like separate Ethernet devices, even though the 4 LAN ports and the WAN port aren’t physically separated. (This has the added advantage that it is possible to further sub-divide the LAN ports or bond the WAN and 4xLAN ports back together into a single 5 port switch.)
Keeping that in mind, open a shell into the router and run “ifconfig”. This is the network configuration tool for Linux, which will list the status of all network interfaces when run with no arguments. You should see something like that below:
Starting from the top:
- br0 - Remember that the LAN Ethernet ports and the WiFi radio are two physically separate devices on the circuit board, so Linux needs to create a logical bridge between the two of them such that devices on each network can see devices on the other. All local network traffic is contained within this device, and the bridge can be further interrogated by running “brctl show” to see which other interfaces are linked within it (SPOILER: eth1, vlan0).
- eth0 - This is the physical hardware for the five Ethernet ports on the back of the device. Since we want to segregate this interface depending on which port the traffic came in on, this interface doesn’t tend to be referenced directly.
- eth1 - This is the WiFi radio, which is linked with the local Ethernet under the br0 interface.
- lo - This is the virtual loop-back device inside of Linux, which doesn’t correspond to any hardware, but is an imaginary interface to allow the router to have conversations with itself; an important ability, to be sure.
- vlan0 - This is half of the virtual segregation between the four LAN ports and the WAN port. In this case, vlan0 is the four LAN ports, and is bonded with the WiFi radio through br0 for all local traffic.
- vlan1 - This is the single WAN Ethernet port, to be plugged into your DSL or Cable modem. The great divide between “inside” the network and “outside” the network happens between vlan1 and br0, and this is where all of the QoS rules are applied as packets leave the network.
- [ppp0] - Depending on exactly how your modem is configured, you may also see an additional device, which is the PPPoE tunnel provided by your ISP allowing you to get traffic out of their network and onto the Internet at large. Our modem happens to handle this tunnel itself, so it issues our router a DHCP lease on the ISP’s internal network and passes all our traffic through the tunnel automatically. Since this replaces vlan1 as the gateway to the rest of the Internet, if this device exists, it is likely the QoS rules are applied to this interface instead of vlan1.
So that is the flow path of network traffic through the physical hardware of the router itself. By drawing a virtual line between vlan1 and br0, Linux is able to isolate the local network from the Internet, giving various advantages including NAT, a firewall, and the ability to selectively shape and prioritize traffic as it leaves the high-speed local network.
The question finally becomes how is this traffic prioritization actually done inside of Linux? Where do all of the settings in the QoS pages of Tomato’s web interface go?
As to where all of the settings go, the answer is that they are stored in the router’s nvram, which is a part of the internal flash storage used to store all of the key=value pairs needed to configure the router once it boots from the immutable root file system.
This is why it is so easy to completely wipe your router by holding down the reset button for ten seconds; the Linux file system hasn’t changed since the day it was installed.
The only thing that doing a hard reset of the router does is erase the short list of variables which you set through the web interface.
You can see all of them at once by running nvram show, but to extract a single example from the database, running nvram get qos_orules shows how Tomato stores all of the classification rules.
QoS Rules:
Yep. One big hairy line of <’s and numbers. Like I said, this is mostly a “look, don’t touch” adventure for the faint of heart.
But that’s the wrong answer to the right question. Immutable file systems are fun and all, but what does Tomato actually do to effect these settings?
Tomato’s QoS system uses two very powerful tools in Linux called iptables and traffic control (tc).
- Iptables is an IPv4 packet filtering and NAT system, which not only uses these rules to classify traffic as “high” or “low” priority, but also handles routing between the different network interfaces set up earlier and all of the address translation between inside of the network (192.168.1.0/24) and the rest of the Internet (which by the way, bought IPv4 another good decade before it now badly needs to be upgraded).
- tc (traffic control) is a large set of different strategies to buffer and reorder packets, based on their priorities assigned by iptables based on the given rules. The full implementation of tc gives an outstanding selection of flexible queuing disciplines, but of course Tomato is using a stripped-down version which only supports the three strategies deemed needed for the application; pfifo_fast, sfq, and htb. This prevents us from playing with more interesting statistical disciplines like red, but should be enough for any typical household network. I’ll go into all of these in more detail later on.
iptables
Iptables is a packet filter and routing system, which means it has not one, but many long lists of rules which it uses to decide what to do with and where to send each packet that the router comes in contact with. When iptables sees a packet destined for google.com, it has rules that tell it that google isn’t inside the network, so it sends the packet to the vlan1 interface to go on it’s merry way off to the Internet. Most of the time, this is all that iptables does; play traffic cop telling everyone where to go. Tomato uses another feature of iptables, which is the “mangle” table.
Iptables can be used to modify packets as it handles them.
We specifically want it to use the classification rules used earlier to “mark” packets as one of our desired priority levels before passing the traffic onto tc to be queued for delivery.
This “chain” of rules can be found by asking iptables to list the QOSO chain from the mangle table.
# iptables -t mangle -L QOSO:
The first three rules are for initial setup, but you’ll notice that every line that targets (starts with) CONNMARK corresponds to one of the classification rules written earlier. Iptables walks down this list until it can match a rule, at which point it uses the corresponding “set-return 0x#/0xff” to mark the packets for tc and considers the matter closed (which is why order matters if a packet would match more than one rule).
You can spend a lot of time poking around the rest of iptables rule set (using iptables {-t filter | -t nat | -t mangle | -t raw} -L) and eventually get a really good idea of how every single packet is directed through this rat’s nest of interfaces, but that is beside the point (and this blog post has already spiraled into a three-part trilogy).
tc (traffic control)
Iptables looks at each packet, and maybe affixes a sticky note saying “HEY! This is important!” but iptables makes no effort of doing anything about it. As iptables processes packets, it blindly fires them off towards the proper network interfaces with no regards to priority, available bandwidth, or common courtesy; this is where tc comes to play. Once iptables has directed the packets to an interface, tc catches them, and places them in a set of queues/buffers attached to each interface to deal with the inevitable fact that iptables will direct packets faster than they can leave the router. Just as the long line of velvet rope smooths out bursts of visitors to the Haunted Mansion, tc smooths out bursts of packets all headed for a single interface of finite bandwidth (anyone who has been to Disneyland, consider why the Haunted Mansion is a particularly good example).
THIS IS WHERE THE PROBLEM IS! (kind of)
Remember those excessively large buffers all over the Internet I talked about earlier? This is where one of them can live, if you go in and crank the buffer up to eleven. Granted, it is only one, and buffer bloat is unfortunately a systemic issue, so whacking this one only exposes the buffers hiding in the network drivers and the hardware and the modem (etc etc), but it is a piece of the puzzle that is easier to fix than most (yeah, everything we’ve done so far is relatively easy; you see the problem). As we’ll see, Tomato gives each class a 128 packet buffer, which may seem like a lot when you figure out how long it takes to upload 128 1500 byte packets. I’m show that the specific buffer used handles dropping packets from this queue fairly well, and the edge cases where 128 packets really is too much buffer are arguably contrived.
The basic building block of tc is the qdisc, or “queuing discipline.” Each physical interface (eth0, eth1), and any virtual interfaces of interest (vlan1/ppp0), have at least one if not more qdiscs attached to it telling tc how to treat traffic heading for that interface. The three qdiscs available in Tomato are the pfifo_fast, the sfq, and the htb:
Pfifo_fast is one of the simplest queuing strategies, and the default for every hardware interface. It stands for “packet first-in first-out,” meaning that it accepts every packet as it is sent to the interface and added it to the end of a list. Every time it is possible to send a packet out on the interface, the packet on the top of the list (the first in) is sent out (as the first out), much as the first person to get in line at the post office is the first to be serviced. This would be a single pfifo; pfifo_fast adds the additional feature that it is actually three separate queues.
Packets entering this set of queues is put into one of the three queues based on the type of service bitfield contained in every IP packet.
Pfifo_fast contains a list of all possible values of this 4 bit TOS field and which of the three bands the packet should be queued on, which can be seen by running tc qdisc show dev eth0.
Once one of these pfifos is filled, additional packets added to it are dropped and disappear, just as they are expected to.
When bandwidth is available, pfifo_fast sends the first packet from the lowest non-empty queue, which means that as long as there is packets in pfifo zero, pfifo one and pfifo two get zero bandwidth.
Not very nuanced or “fair,” but computationally cheap and good enough as long as the link isn’t near being overwhelmed.
The reason this first-in first-out queue is unfair presents itself when it gets close to full. Once a fifo fills and starts to drop packets, it will continue to drop packets until it eventually sends it’s first packet. At that point, a single slot opens at the end of the line, which is given to the first packet to arrive after that moment. Statistically, this means that the slot is given to whomever is sending packets at the router the fastest, but they deserve the spot in line the least since they probably got most of the previous spots as well. Compare a large file upload, which will continue to send packets until the cows come home, to clicking on a link in a web browser, which spawns something on the order of 3-20 packets in quick succession; if there is only one or two fifo slots open, the file upload is probably going to get them before the web browser, while the web browser really needs all of its packets sent before it can get any useful work done but stands a good chance of most (if not all) its packets being dropped.
This brings use to the somewhat better sfq, or stochastic fairness queue. Like a pfifo, the sfq doesn’t classify traffic in any way (so we still haven’t used all our classification rules yet), but what it does do is a much better job of giving each distinct stream of traffic a fairer share of the total available bandwidth. This is done in much the same way that students are evenly split between teaching assistants handing out tests, or conference attendees registering at the kiosks.
This fairness is enforced by dividing the queue into several lines based on some intrinsic property. For people, the most common property used is the first letter of your last name, splitting you into one of a few ranges of the alphabet. Sfq does the same thing for IP traffic, but uses the source and destination IP addresses and ports to try and group together packets that are of the same stream, and uses these values to divide the traffic between 1024 seperate fifo queues, which are serviced round-robin, where outbound packets are taken one at a time from each non-empty queue before returning to the first queue. Three distinct traffic flows each get one third of the available bandwidth, assuming the likely chance that each of the three ends up in a different one of the 1024 queues. The sfq then puts a cap on the total number of packets that can be waiting between all of these queues (hard-coded to 128 in Tomato), after which it starts dropping packets as well. Unlike a fifo where it drops the arriving packets when it becomes full, it drops packets from the longest of the 1024 queues, which is probably the flow unfairly consuming the most bandwidth. Now, even if there are 128 packets from a large file upload in the queue, when a short burst of eight packets come from a different flow, the burst is put in their own unique queue, and enough packets are (fairly) dropped from the largest flow to make room for them.

Unfortunately, just as Octomom could show up with 15 people with last names starting with S, one flow might happen to end up sharing a queue with another bandwidth hogging flow, and that just wouldn’t be fair (in the same way as fifos). To get around this chance that even 1024 separate queues isn’t enough to divide all the flows, sfq decides to change the rules of the game every ten seconds, and reshuffle the queues so two colliding flows only collide for a few seconds before being reshuffled. This perturb interval can be changed from ten seconds, but too short and you waste effort constantly reshuffling flows, too long and colliding flows have to suffer with sharing bandwidth for longer than pleasant.
There is the one slight issue with this reshuffling in that queued packets can be shuffled out of order when they’re perturbed. Imagine if you were waiting in line to pick up your name tag for a conference, and suddenly someone went up and changed the sign separating queues from “by first letter of last name” to “by first letter of first name.” There would be a mad dash as everyone rearranged themselves to put themselves in their new assigned queues, and people would inevitably end up out of order versus their original arrival order. Not a serious issue, since the Internet is designed to handle packets being reordered, but this is certainly one way that it happens.
The last of the queuing disciplines used in Tomato is the htb, or hierarchy token bucket, which finally uses all of the classification rules that we wrote and had iptables tag packets based on. The htb uses virtual “tokens” as bandwidth IOUs to limit flows to their allocated bandwidths, and is hierarchical in that it is willing to sell bandwidth in exchange for these tokens from higher priority queues first. This is better than the pfifio_fast set of three queues because once the highest priority of traffic spends all their tokens, lower priority queues get the chance to spend some of their own while the highest has to save up tokens to send the next packet. This prevents low priority traffic from being completely starved by higher priority traffic, while still ensuring that high priority traffic gets as much as it deserves (which we originally decided was 70%.
Of course, while we designed our rules so that the highest class is guaranteed 70% of the bandwidth, it is unlikely that DNS resolutions are going to take that much bandwidth, so lending and borrowing tokens between classes is allowed, so that lower priority classes can borrow tokens from highers when not needed.
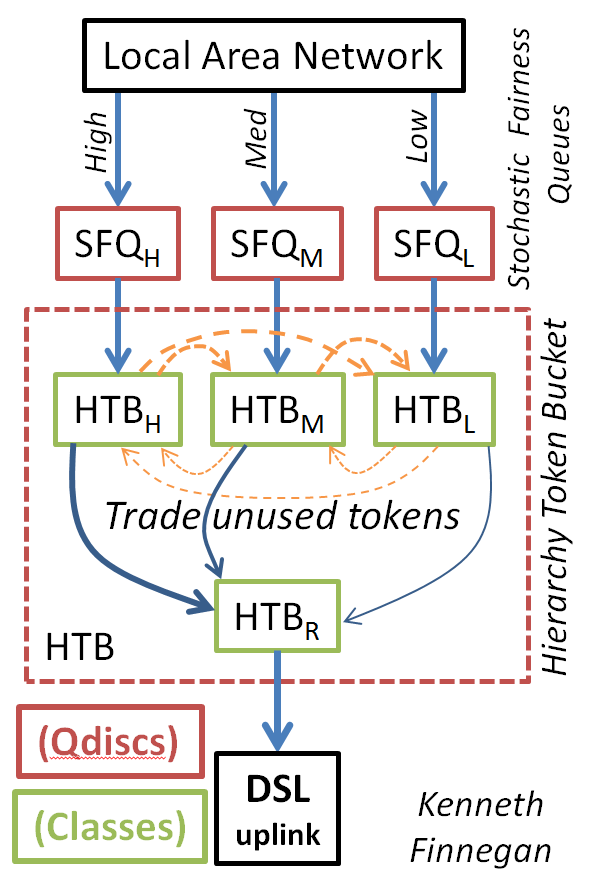
We can finally look at the entire queue pipeline as it is implemented in Tomato. Starting at the top, LAN traffic bound for the internet is categorized by iptables into a separate stochastic fairness queue for each class of traffic, to fairly reorder all of the “high” streams into one stream, all of the “medium” streams into one stream, etc. This set of streams mixed fairly is then fed into the hierarchy token bucket, where they are each apportioned an amount of bandwidth (based on our percent settings on the basic QoS tab), which they can trade as needed. These token bandwidth IOUs are then spent to get in line in another layer of token bucket (HTBR in the diagram), which ensures we don’t spend more tokens than bandwidth can be handled by the modem, which was the entire point of this whole affair. This second layer of protection means we can actually ration out more than 100% of the available bandwidth between the classes, but if higher classes do happen to spend all of their shares, the lowest priorities never get a chance to spend tokens at all and are again completely starved out of the link.
To see this implemented in Tomato, and to monitor how many packets are passed through and buffered in each of the SFQs, ssh into your router and run the following commands:
# [tc -s qdisc show dev vlan1](https://gist.github.com/2279687#file_qdisc.sh)
Notice that there are six separate queuing disciplines attached to the out-bound interface, the one HTB and the five SFQs for highest (#10) to lowest (#50) priority.
# [tc -s class show dev vlan1](https://gist.github.com/2279687#file_class.sh)
The corresponding six classes are all attached to the 1:1 HTB, but each class for a different priority is attached to their corresponding “leaf” qdisc, and the final HTBR is connected to the root, which is finally fed to the physical hardware and sent on its merry way to the Internet.
These two command strings are probably what I find most useful, in conjunction with the QoS_Details page, for writing QoS classification rules. Being able to monitor each htb class and see how many packets are being handled per second, how big those packets are on average (via the “rate” number), how full the 128 packet sfq is (“backlog”), how starved lowest priority traffic is (“dropped”), and how token buckets lend and borrow tokens and ceiling tokens (which are the allowed bandwidth for each class which isn’t guaranteed) gives you a good idea of the dynamics of the system. Having it wrapped around watch in the background (“watch tc -s class show dev vlan1”) lets me see heavy flows migrate from class to class much easier than trying to follow them in the giant list of connections through the website.
So that’s it. Hopefully this series [1], [2], [3] was not too outrageously confusing, and at the very least provided you links to a useful set of man pages to start reading on the subject. I have very deliberately spent more time explaining the mechanism than saying what the “right” set of rules is to make your Internet better, because your rules will inevitably be different than mine. You’ll have to go fishing for yourself.
Again, I’d like to thank Jim Gettys, and anyone involved with the growing BufferBloat project at large, for putting a tremendous amount of work and effort into the issue and bringing it to my, and now your, attention.
Finally, to wrap up this series, I’ll leave you with a 10 minute snapshot of what I can only describe as my Internet connection hunting during a simultaneous upload and download test, just to show you what broken can be: