Introduction to Buffer Bloat

For the last six months I’ve been quietly following Jim Gettys, and the development of the Bufferbloat project, trying to bring attention to the contemporary issue of “bufferbloat.” The problem basically comes down to the fact that one of the original unwritten golden rules of how the internet handles traffic has become violated.
The vast majority of internet traffic is sent over TCP/IP, which is two specific protocols stacked on top of each other to give computers a very powerful tool to transport information throughout the internet. The bottom layer is the Internet Protocol, which does nothing more than indicate where a packet came from and where the packet is to be sent, based on the two computer’s IP addresses, which are the numbers you often see in the “192.168.1.100” or more recently “2001:0:5ef5:79fd:1414:30:01b3:4b22” format, and are comparable to your house’s mailing address. IP is used as a wrapper for some form of transport protocol, which is then used as the wrapper around your data. There are countless different options for these transport protocols, but the two most common are UDP, which are one-off messages, and TCP, which is for guaranteed delivery of large streams of data. Since most of the internet deals with large streams of data (downloads, web pages, pictures, early file sharing, etc), TCP is very important.
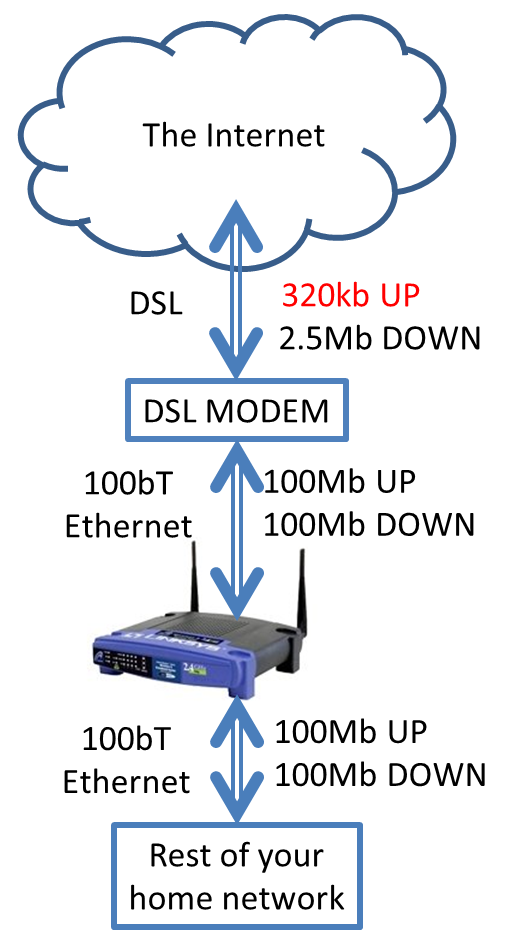
One of the many challenges that TCP has to deal with is “congestion.” This is where data traffic starts to overwhelm one of the many connections in the mesh of the Internet. The widest-deployed example of this is actually your own home network; you typically have a DSL modem, a router, and one or many more computers, as shown above. If you start a large upload, such as a YouTube upload, your computer will very merrily send video data at 100 million bits per second over your Ethernet cable to your router, which will gladly send it to your DSL model at 100Mb, which is then faced with a profound dilemma; the modem is getting data WAY faster than it can cram it up your DSL connection, which in my case happens to have 0.3% the bandwidth of a 100bT Ethernet network. What the heck does your router do with all this extra data?
The original designers of TCP came up with a very clever solution to this dilemma: throw the excess data away. Just drop it. Boop. Gone. They then designed TCP to expect this indifferent treatment by Internet infrastructure and even be able to use these drops to the user’s advantage. When a TCP connection is made between two computers, they have NO idea how many or what network connections are between them, so TCP starts off assuming the network can barely handle any traffic. Once that first packet gets successfully delivered, TCP goes “Hey, maybe we can send more data!” So TCP sends twice as many packets and watches for drops. TCP continues to exponentially increase how much data it’s willing to try and send at once until eventually something along the path yields under the load and drops a packet. TCP can then use this dropped packet as indication of a problem and backs off, assuming it has found the upper limit on the network speed. TCP then continues to probe the network more gently, watching for if the network somehow gets faster (via a new route being available, or other traffic sharing the path ending) and can start sending data even faster.
The challenge is that the sender can’t know right away when a packet is dropped. The sender doesn’t find out that a packet was dropped until the receiver complains, which when you’re dealing with an Internet connection between computers on different continents, can be a measurable amount of time due to nothing more than the speed of light. You start talking about satellites, and this minimum time gets even worse.
So TCP congestion avoidance greatly depends on how quickly it finds out about one of these dropped packets. As TCP is probing the network, it will continue to assume the network has more and more bandwidth until it sees one of these dropped packets.
The problem is that this is an unwritten golden rule. You introduce the explosive growth of the internet over the last 20 years and you start seeing people miss this unwritten memo and applying the more intuitive solution of throwing a buffer at the problem. When you’re the engineer designing a DSL modem, it’s really easy to talk yourself into adding a huge buffer so you never have to drop one of the customer’s precious packets. Maybe there will be less traffic in a little while, so why not hold on to these packets and try sending them then?
The problem is that RAM has gotten really cheap. Why only use a 100kb buffer in the modem when you can’t even buy RAM chips smaller than 2Mb? Why not just use all 2Mb for the buffer?
In my example network above (which is actually my network), a 2Mb buffer on my DSL modem would be able to hold 6 seconds of traffic. You can construct a scenario where a TCP connection sends a packet which has to wait in line for 6 seconds before it gets sent by the modem, but it does eventually get sent by the modem. The problem is that the packet shouldn’t have been sent.
A packet hanging around for 6 seconds before getting passed on to the next node in the network doesn’t really bother TCP too much. As long as packets aren’t dropped, TCP just figures “huh, I guess these two nodes are just really far apart…“ The problem is that at the speed of light, six seconds apart is a little more than 1.1 million miles, or almost five times the distance to the moon. TCP may not be bothered by this, but humans sure are, and it’s unlikely you’re trying to upload YouTube videos from the moon.
Imagine if every time you opened a webpage it didn’t even start loading for 6 seconds. For some people, you may not even need to use your imagination; I’ve seen Internet connections that were this bad. The silly part is that your request isn’t even leaving your house for most of those six seconds. Once it gets past your modem, the request only takes maybe 100ms to complete, which wouldn’t bother you by itself.
So your home modem has started buffering way too much for how much traffic it can actually handle. For the home modem to be more honest about how much traffic it can handle, it would have to start dropping packets much sooner, but because that feels like a bad idea, equipment manufacturers shy away from it. This isn’t only happening in home modems. Routers, switches, Ethernet cards, operating systems, wifi drivers, critical ISP infrastructure; everyone is hanging onto packets for longer than they should, and it’s making our internet worse than it should be.
This post originally started out as a quick intro to configuring the QoS settings in Tomato, the custom firmware I run in all my routers, but spiraled so much out of control that I’ll leave that to an entirely separate blog post in the future. I’ll first talk about how to use the user friendly web interface to write your own rules, then talk about the gritty internals of the system and what Linux does with your packets after it classifies it based on the rules you give it.
Jim Gettys has given several good talks, and written many good articles examining different facets of this issue, and he is quiet a bit smarter than me, so if he and I differ on any details, I cede my error. My explanation of TCP’s behavior is also severely simplified to demonstrate the point; not only are real world implementations of TCP more nuanced, there are more different implementations of it than I have fingers.